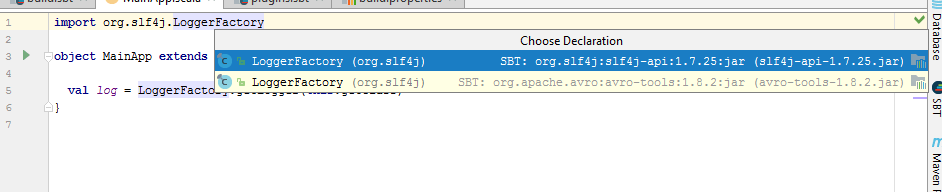
Using Avro Schema in JVM based applications
Like Protobuf, Apache Avro is specially suitable for organizations with polyglot development stack. Data serialized through one language can easily be deserialized in other language on the other end of your messaging platform. This is one of the supported serialization for Confluent platform.
The benefits of Avro over other formats including Protobuf and Thrift is the usage both data and schema in serialization and deserialization. So you don’t need to generate types and still be able to use the data using the available schema. Having said that, it is really not necessary for the schema to be put on the wire for sending it to some other party. This is the approach used by Confluent platform where a separate Schema registry is introduced which is used to contain this meta data. So before sending data over to Kafka, a schema must be already registered with Schema registry. Only Schema Id is put with data on Kafka brokers. As the data reaches a consumer, this schema Id is used to pull the schema definition from the registry and used for deserialization.
The current version of the specification is 1.8.2. You can get more details from the specification page.
Options for Serialization / Deserialization
There a few options for serialization / serialization into using Avro schema. After serialization, we can send it over wire. This can be received on the other end, and deserialized. The sender and receiver don’t have to be implemented using the same languages / platforms.
Generating Java Classes
In this approach, avrotools is used to generate Java classes from the schema file. More than one file can be used here. It is also possible to have more than one record in the same avro schema file, but avrotools would still generate separate files for these types.
You can also directly create Scala class using the following:
Using Parser for Serialization / Deserialization
In this approach, we directly use the schema files in our code and use it for generating records. I am sure, this would look a little loose design to you as the records would be generated in a key / value fashion. Actually a GenericRecord is created, which can then used to build up an object.
Avro in a Scala Application
Let’s create a simple Scala SBT Project. We are naming the application as StudentApp.

Create App
Defining Avro Schema
First of all, we need to define schema for types expected to be shared between applications. These schemas can be used to generate types in the language of choice for applications.
The schema introduces a type Student in studentModels schema. It has three properties, which are student_id (int), first_name (string) and last_name (string). The last of these are nullable.
Using avro-tools
Since we need to use it in a JVM based application, we can use Java implementation of Avro to generate Java types using the above schema. Let’s first download avro-tools for 1.8.2 specification from Apache.

Download Avro Tools
Here we are compiling the schema and generating types in java/generated folder.
But when we open type, we get all these indication of errors, and sure enough, the code doesn’t even compile. So what are we missing?

Generated Code Error
In order to fix this, we need to add the following dependencies to our build.sbt file; and sure enough, the compilation is successful finally.
Now we can simply use the generated type in our Scala code. Here we are simply creating building a Student instance. Later, we are just printing the properties of the instance to the console.
Download Code

Download code