Scala Macwire: Inject all Implementations of a trait for factory pattern
Macwire is an amazing DI (Dependency Injection) container for scala. It allows to wire up the dependencies required by a type to instantiate itself as long as the type is registered with it.
If you are coming from C# background and are used to Unity framework then you must be used to register interfaces and implementations with Unity. Macwire is a bit different as we don’t need to provide such bindings. It automatically detects the binding between a trait and concrete type as long as the concrete type is registered with the macwire framework.
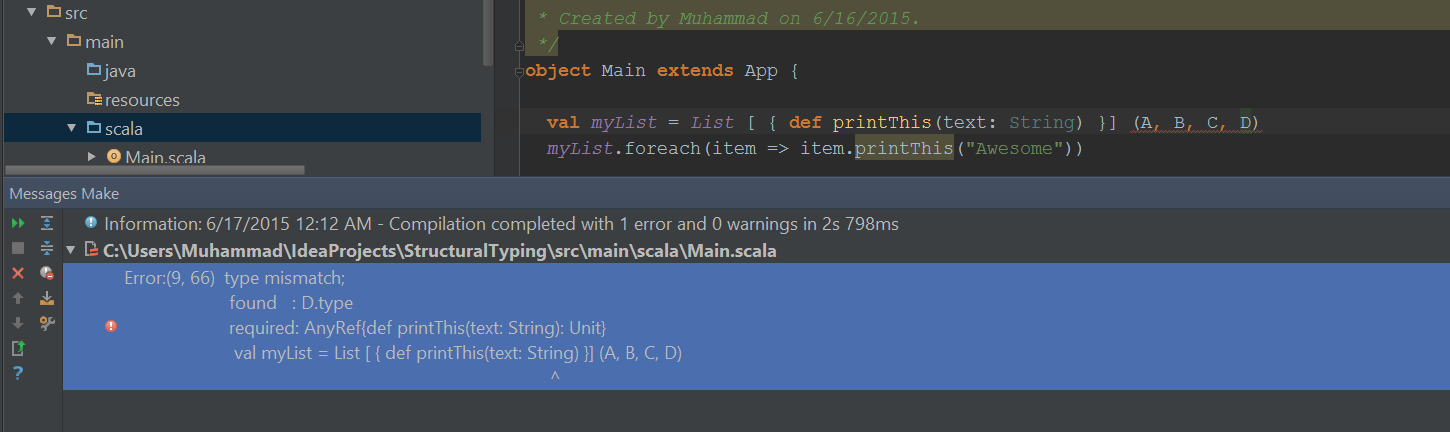
While implementing factories, you might be used to inject all the implementations of an abstract type (interface) in the factory constructor. Unity allows such injections if it finds more than one implementation of an interface. The problem with macwire is that it doesn’t automatically allows such injections. This is because of the way it works. It keeps a track of the registration in the current context and traits implemented by these registrations. If there is a request for injection a trait implementation in the constructor of a type being constructed, it just looks at these registration and injects the appropriate concrete type implementing the trait.
Macwire allows multiple registrations of concrete types even if they implement the same interface but it cannot directly inject them all even when a construction requires a collection of trait implementations. Au contraire, it results in a compile time error. In this post, we are trying to find a solution to this problem.
Let’s first add the macwire dependencies to our sbt file. It would make sure that the necessary libs are copied in your build.
As you compile it, you should be able to find these libraries in the External Libraries section of your project.

macwire
Now let’s introduce a trait named Operation. Here we have two implementations of the trait. They OperationFirst and OperationSecond. The trait requires implementation of a method execute. It also requires a field operationType identifying the type of operation. This can be used by factory responsible to provide Operation based instances.
OperationFactory provides an instance of an object of a type implementing Operation trait. It uses key to determine the required Operation type. In case, it is not able to find a type for the specified key, it throws a IllegalArgumentException.
We need to wire up these types using Macwire. Here MyModule is using Macwire’s wire[T] to register these types. As discussed above, it actually results in the binding between these types and traits implemented by these types. Here we are registering OperationFirst and OperationSecond, which should define their binding with Operation trait. We are also registering OpertationFactoryImpl. The module just has one public property. Accessing the property should result in the creation of the whole object graph from Macwire.
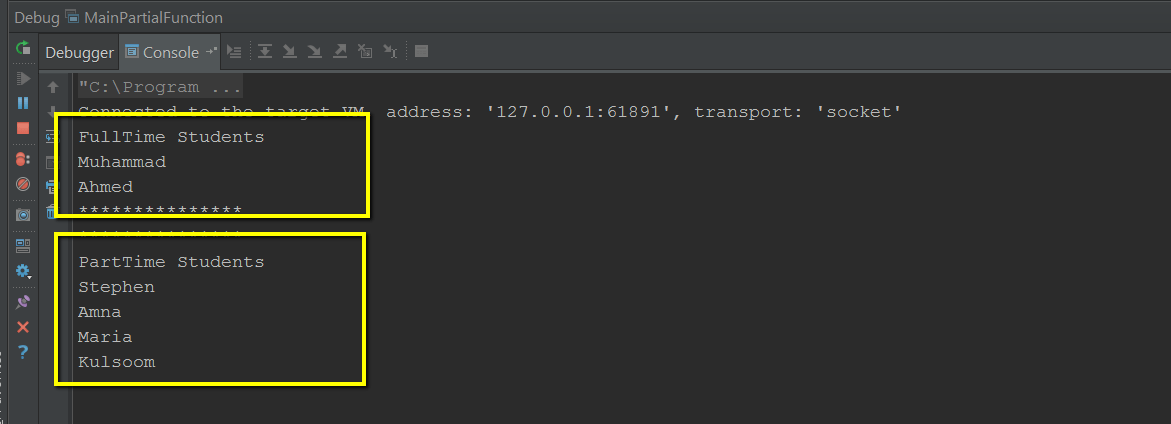
In the code below are getting the OperationFactory object from MyModule instance. We are trying to get an operation by providing “first”, “second” and “third” as keys for the factory. It looks like the code should work fine for “first” and “second” where factory can provide the OperationFirst and OperationSecond instances respectively. Since it is not able to find an implementation of Operation with “third” as OperationType, it should result in an exception. The code catches the exception and prints its message.
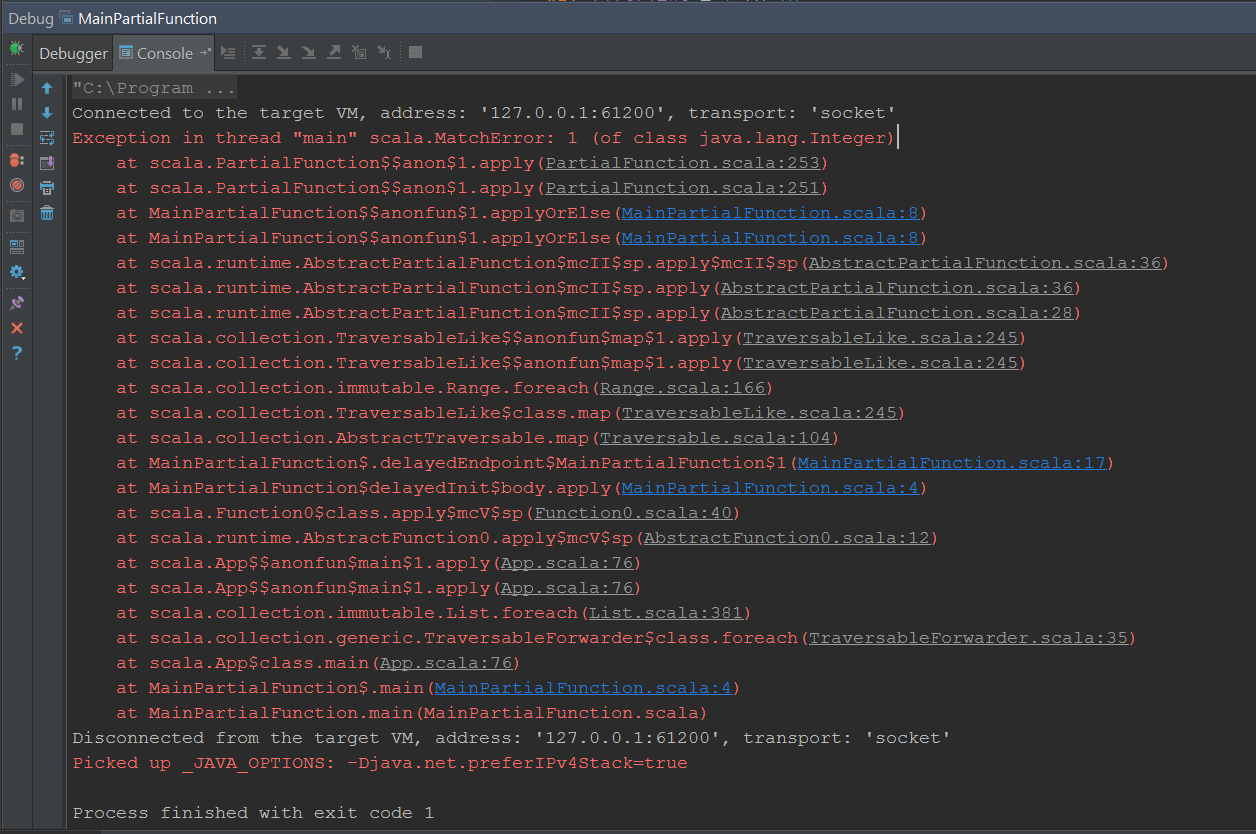
As we compile the code, the compiler claims for the required implementation of List of Operation based types. Actually Macwire is trying to find any such registrations. Since it is not able to find such registrations, it is resulting in this compile time failure. Yes, more than one registrations of type implementing Operation trait is of non help to Macwire.

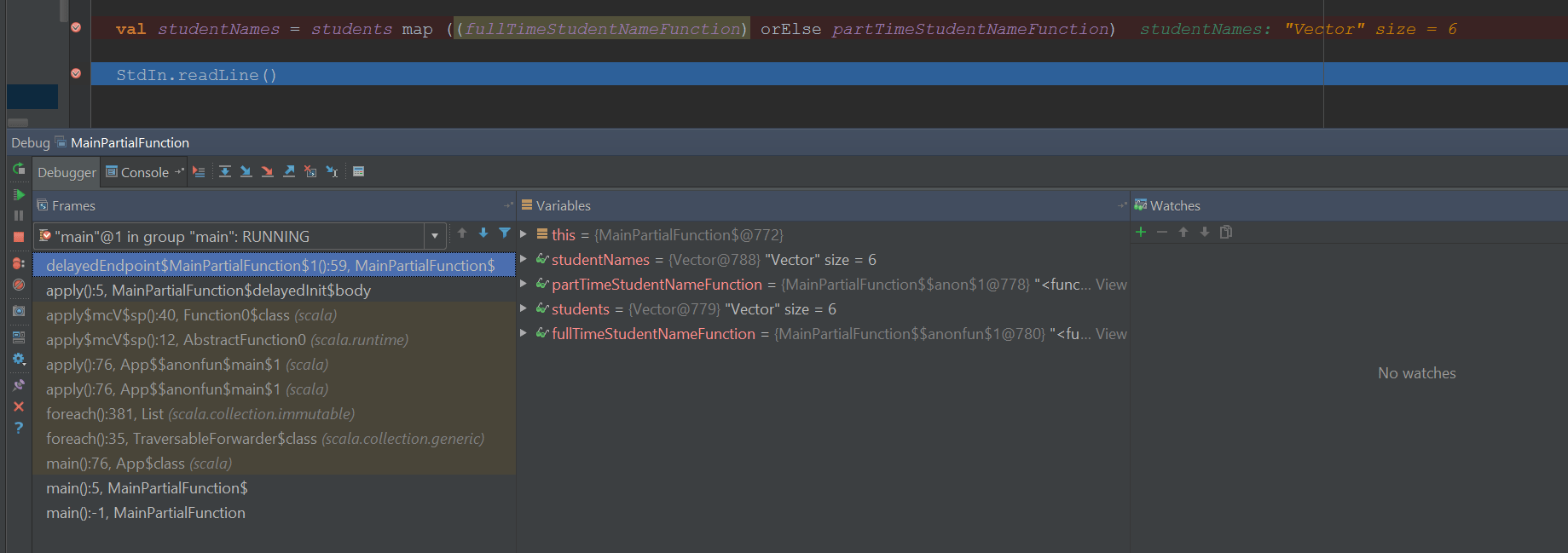
It is actually very simple to fix. Since it is trying to find a List of Operation in the current context, we can provide this with it. Here we have just created a List of all wired up instances of Operation types. We can keep it lazy.
Now the code compile fines and behaves as expected when we debug it.

Zindabad!